|
Le informazioni contenute in questi appunti si riferiscono principalmente al PIC16F877A (vedi datasheet), ma possono essere applicate a molti altri modelli con periferiche uguali o quasi.
In ogni caso, una lettura del datasheet appropriato, è obbligatoria. |
Ciclo istruzione (o ciclo macchina)
In qualunque microcontroller, le istruzioni nella memoria programma, vengono eseguite in sequenza, una dopo l'altra. Per far questo, è necessario un orologio (clock) che scandisca il tempo per eseguire le varie fasi.
Nei PIC questo compito è svolto dall'oscillatore principale (a quarzo, risonatore ceramico, ecc.).
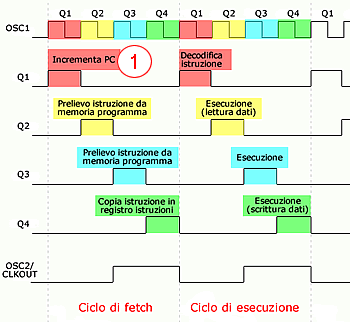 |
La frequenza generata da questo oscillatore, all'ingresso OSC1, viene divisa internamente per 4 per generare 4 periodi di clock (Q1, Q2, Q3, Q4) e, la frequenza risultante (Fosc/4), viene resa disponibile all'uscita OSC2/CLKOUT.
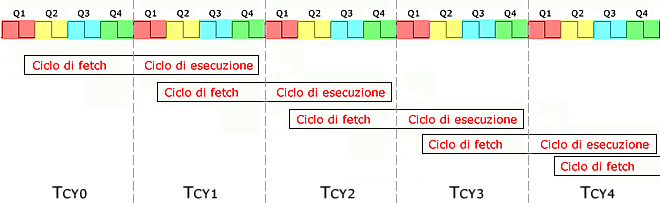
I 4 periodi di clock, messi assieme, formano 1 ciclo istruzione (o ciclo macchina) e servono per scandire le fasi di caricamento (fetch) ed esecuzione di ogni istruzione.
Dalla figura si vede che, per il ciclo di fetch (prelievo dell'istruzione), è necessario 1 ciclo istruzione e, per il ciclo di esecuzione è necessario un ulteriore ciclo istruzione.
Se ne deduce che, per eseguire ogni istruzione, sono necessari 2 cicli macchina. Tutto questo è vero ma... nella realtà... si riesce ad eseguire 1 istruzione per ogni ciclo macchina.
|
L'architettura Harvard permette di sovrapporre il ciclo di fetch, dell'istruzione attuale, al ciclo di esecuzione dell'istruzione precedente. Come vediamo nella figura seguente, soltanto il primo ciclo macchina (Tcy0) non avrà sovrapposto un ciclo di esecuzione, mentre tutti gli altri cicli macchina (Tcy1÷Tcyn) avranno sovrapposti ciclo di fetch e ciclo di esecuzione. Con questo trucchetto, chiamato "pipelining", ogni istruzione, "sembrerà" che venga eseguita in un solo ciclo macchina.
Tuttavia, alcune istruzioni, che devono eseguire un salto ad altro indirizzo di memoria (call, goto, retfie, retlw, return), avranno bisogno di 2 cicli macchina, per essere eseguite.
Mentre queste (decfsz, incfsz, btfsc, btfss), avranno bisogno di 2 cicli macchina, soltanto se devono effettuare un salto di istruzione.
indirizzo | istruzione
0000 movlw A7h
0001 movwf portc
0002 goto 05h
0003 clrf portb
0004 incf portb
0005 clrw
0006 movwf porta
|
Prendiamo ad esempio queste righe di programma, dove, a sinistra, c'è l'indirizzo nella memoria programma e, a destra, l'istruzione che vi è memorizzata e vediamo come vengono trattate ed eseguite dal microcontroller.
Il PC (Program Counter), è un registro che tiene il conto di quale istruzione deve essere eseguita e, precisamente, l'indirizzo di questa, nella memoria programma.
|
Quando diamo alimentazione al PIC (oppure dopo un reset), il PC viene impostato con l'indirizzo della prima istruzione da eseguire (che in questo caso è 0000h in esadecimale) nella memoria programma.
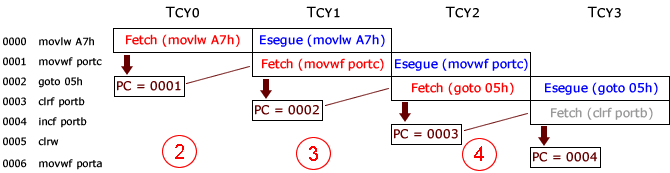
(2) Si inizia con il primo ciclo macchina (Tcy0) che, durante il periodo Q1 (vedi figura sopra, al punto (1)), incrementa il PC, che punterà all'indirizzo della successiva istruzione da eseguire (0001).
Nei successivi periodi (Q2, Q3, Q4) viene letta l'istruzione attuale (all'indirizzo 0000) e copiata nel registro istruzioni.
N.B. Tutto questo viene fatto a livello codice macchina dal microcontrollore, il quale riconosce, solo e soltanto, codici numerici e non le istruzioni assembly che vediamo, le quali servono soltanto a noi umani, per semplificare un pò la programmazione. Le istruzioni assembly vengono trasformate in codice macchina da un software assemblatore (ad es. MPASM), che genererà il file .hex da inserire nel PIC.
 |
|
(3) Nel successivo ciclo macchina (Tcy1), durante il periodo Q1, viene decodificata l'istruzione nel registro istruzioni e incrementato il PC, che punterà all'indirizzo della successiva istruzione da eseguire (0002).
Nei successivi periodi (Q2, Q3, Q4) viene eseguita l'istruzione precedente, viene letta l'istruzione attuale (all'indirizzo 0001) e copiata nel registro istruzioni.
(4) Nel successivo (Tcy2) si ripete il tutto come sopra e il PC, incrementato, punta all'indirizzo 0003 però, stavolta, viene caricata una istruzione di salto (goto 05h) che dovrà saltare le istruzioni agli indirizzi 0003 e 0004, per eseguire quella all'indirizzo 0005.
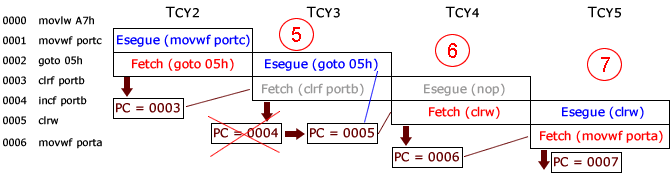
(5) Nel ciclo macchina (Tcy3), durante il periodo Q1, viene decodificata l'istruzione nel registro istruzioni e incrementato il PC, che punterà all'indirizzo della successiva istruzione (0004).
Nei successivi periodi (Q2, Q3, Q4) viene eseguita l'istruzione precedente, viene letta l'istruzione attuale (all'indirizzo 0003) e copiata nel registro istruzioni.
Questa istruzione, è stata caricata seguendo la logica del pipelining, ma non dovrà essere eseguita.
L'esecuzione dell'istruzione (goto 05h) ha modificato il PC, che ora punta all'indirizzo 0005, dove c'è la prossima istruzione da caricare ed ha sostituito, con una istruzione NOP (Nessuna OPerazione), quella caricata precedentemente.
(6) Nel ciclo Tcy4, si ricomincia il pipelining come al punto (2), proseguendo coi cicli (Tcy5 ÷ Tcyn) (7) fino a che non si incontrerà un'altra istruzione di salto, che interromperà il pipelining, come abbiamo visto.
La conoscenza di come vengono eseguite le istruzioni, serve per fare dei cicli di ritardo molto precisi, che andranno scritti, esclusivamente, in linguaggio assembly.